

When we started building Bobsled's first data agent a few years ago, the whole field was focused on one thing: getting an LLM to write better SQL.
Then the agentic models arrived in early 2025, and we learned something quickly. The models were already more than capable of writing SQL. What they lacked was context: the business definitions, the join rules, the hidden gotchas that live in every real data estate but almost never make it into a schema. So we built a system for teams to manage that context: first as a monolithic artifact, like a semantic model, and then as a context layer the agent could reach through a set of tools.
We're now on the edge of a third era. As agent models keep improving — moving from tools a human wields to systems that run long, multi-step tasks on their own — we're heading toward agents that curate their own context, learning from every question asked, every query run, and every piece of feedback received.
Adaptive Learning, which we launched last month, is the first step toward that future. With Adaptive Learning, the agent builds and updates its own context by watching how it gets used. An inefficient run, a negative follow-up, an expensive query: these are all signals the agent can use to do better next time.
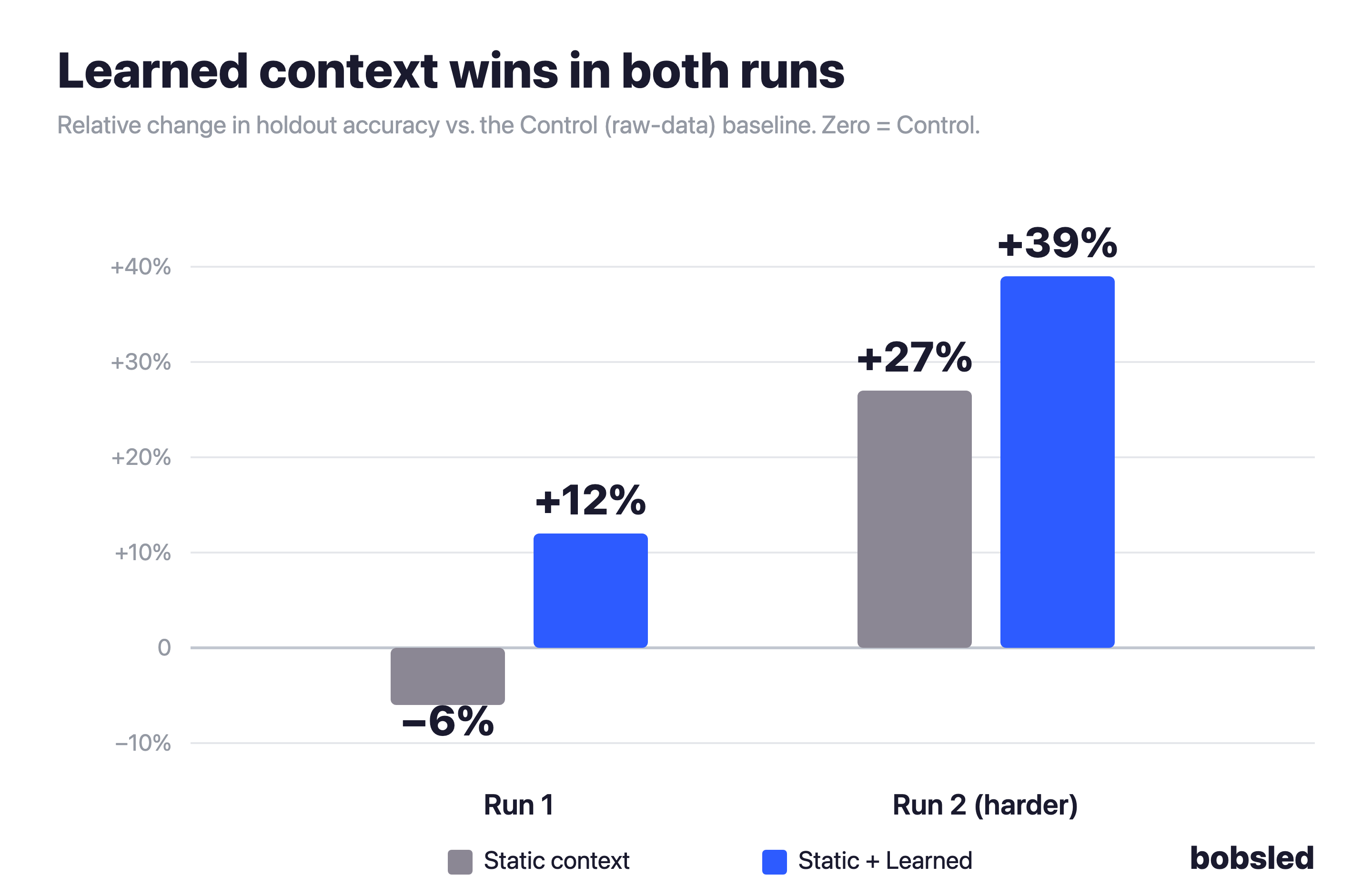
And the impact is real. In a controlled internal experiment, our data agent with Adaptive Learning answered 12% more questions correctly than an agent with no context layer on a set of ambiguous, real-world questions — and 39% more on a harder set. The advantage grew as the questions got harder.
Here's how we measured it.
Measuring the impact of learning
To test Adaptive Learning, we set up a deliberately simple experiment. We cloned the same demo PGA Tour dataset three times and ran the same data agent, on the same model, against the same questions. The only thing we changed was the context each agent could see:
- Control: a basic schema only and raw data.
- Static: a pre-generated context layer: data models and semantic descriptions produced in one pass.
- Learnings: the static context layer plus learnings
We evaluated all three against three sets of questions of increasing difficulty. The first was a well-specified suite of 25 questions:. explicit metrics, clear thresholds, complex SQL. The other two were ambiguous suites we call Run 1 (17 questions) and Run 2 (15 questions). Both were authored independently, both cover the same four diagnostic categories — join gotchas, vague business terms, multi-step synthesis, and open-ended queries — but Run 2's questions are deliberately harder. Before Run 2, we wiped every learning the agent had accumulated and let it relearn from scratch, so it couldn't reuse anything memorized from Run 1.
Our outcome variable was simple: did the agent get the answer right? We scored with a gold-aware LLM judge that reads the agent's final answer and cross-references the SQL it actually ran, so a confidently-worded wrong answer can't slip through.
Finding 1: On simple questions, context barely matters
The first result didn't surprise us. On the well-specified suite, there was little difference between the three conditions. In fact, the Control agent answered roughly 96% of those questions correctly on raw data alone, leaving almost no room for context to help.
The lesson: if you're asking well-specified questions of well-structured data, a modern agent already does fine. A better semantic model and some learnings will help at the margins, but most users won't notice. The interesting signal lives elsewhere.
Finding 2: Learned context wins where static context can't
So we turned to the two ambiguous suites: the messy, underspecified questions real users actually ask. Things like "Who are the best putters?" or "Which courses do pros struggle on?" These don't tell the agent what metric to use, what sample size to require, or how many results to return. With raw data alone, the agent invents a convention, and often the wrong one.
Two things stood out.
Static context alone was unreliable. On the simpler set of questions, the agent with only pre-generated context did not perform materially better than the control. We only saw performance improvements when asked the most challenging set of questions.
Learned context won every time. The agent with Adaptive Learning beat the Control on both runs — and, unlike static context, it never went backwards. The improvement also grew on the harder set, which is exactly what you'd predict if learnings help most where the agent has to invent conventions.
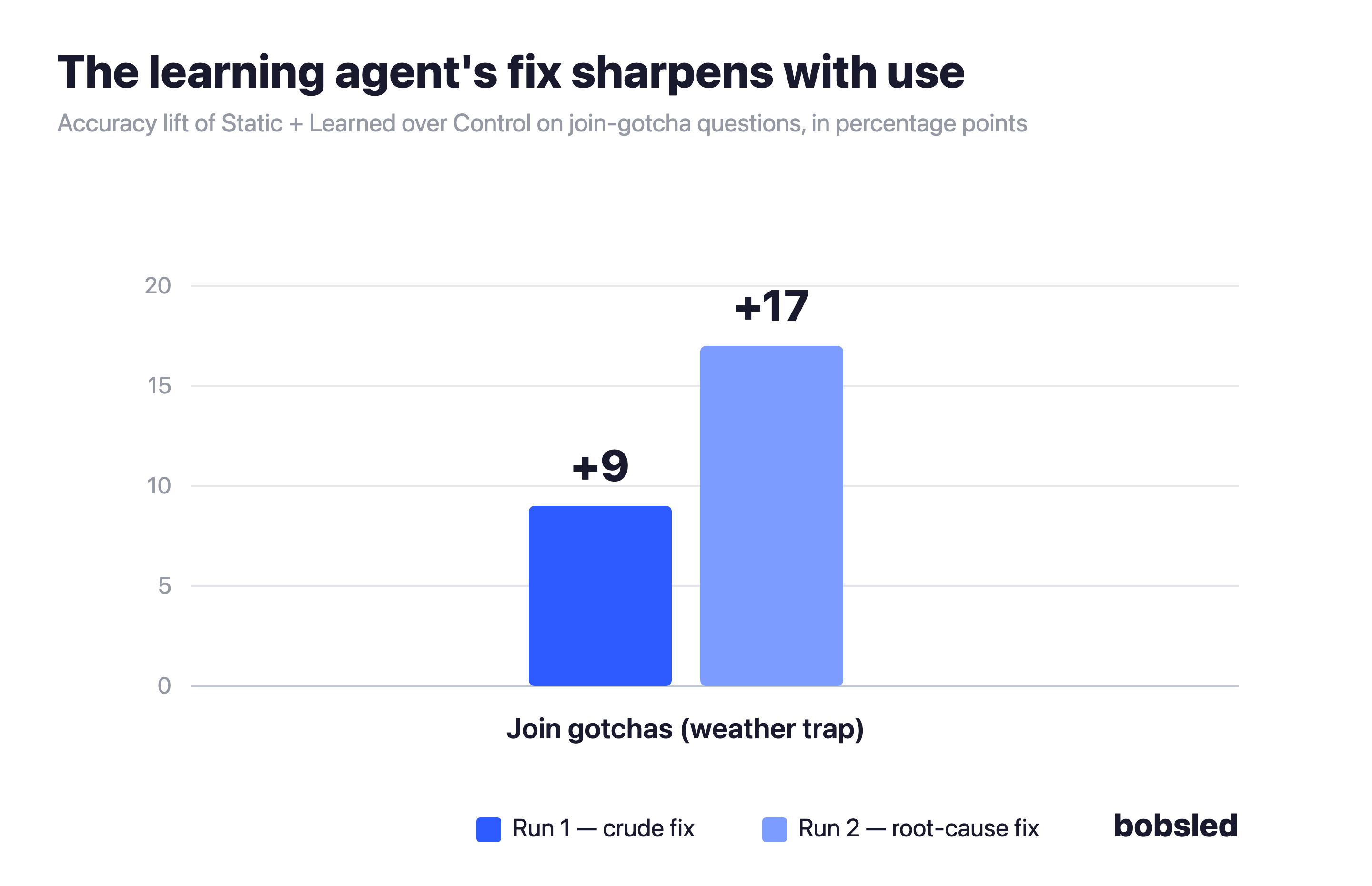
Finding 3: The agent's fix sharpens with use
The clearest sign that the agent improves with use is how it handled a deliberate trap in the data. The weather table has a hidden flaw: the same tournament round is listed once for every year it was played. So when the agent joins weather to scores the obvious way, each score gets counted 7 to 9 times, the averages come out wrong — and nothing warns you it's happening.
In Run 1, the learning agent spotted the problem and patched it with a crude fix: just delete the duplicate rows. That lifted weather questions by 9 points. In Run 2, with more usage to learn from, it found the actual root cause — the duplicates come from different years — and fixed it properly by matching on the year too. That lifted the same questions by 17 points, nearly double. This is the kind of subtle, dataset-specific gotcha nobody could reasonably expect a customer to document up front. But the learning agent surfaces it from observed usage, and refines it as it sees more.
Conclusion
In many ways, the findings here likely under-report the potential impact of learnings on data agents. The demo dataset used for our tests is orders of magnitude simpler than even the most well-maintained business data estate. Additionally, the advantage of adaptive learning compounds over time: the more questions asked, the more learning occurs, and the bigger the split is between pre-declared context and learned context.
But the bigger opportunity extends beyond context. A mature learning system will also optimize the other layers of the agentic analytics stack, which include not only agent prompts and graphs, but also the data engineering layer itself.
Want to see what a learning data agent does on your own data? Book a demo here.