
Every agentic analytics POC looks great at launch. Six months in, the data has changed, the business has moved, and answers start degrading.
The problem? Context drift. Context has changed, but your context layer has not.
Today, we're announcing Adaptive Learning, a new approach to keeping your agentic analytics system current as your data, users, and business evolve. Teams working in Bobsled now get a set of agents that continuously monitor and suggest improvements, with full control over what gets applied and when.
Here's how it works:
- Identify: Agents automatically monitor activity, identify poor user experiences, and recommend steps to fix it in the future.
- Review: Start by reviewing all proposed changes in the learning library and then delegate more to the agent over time.
- Fix: Learnings go beyond context management to data modeling and prompt engineering as well.
Identify context drift with generative feedback
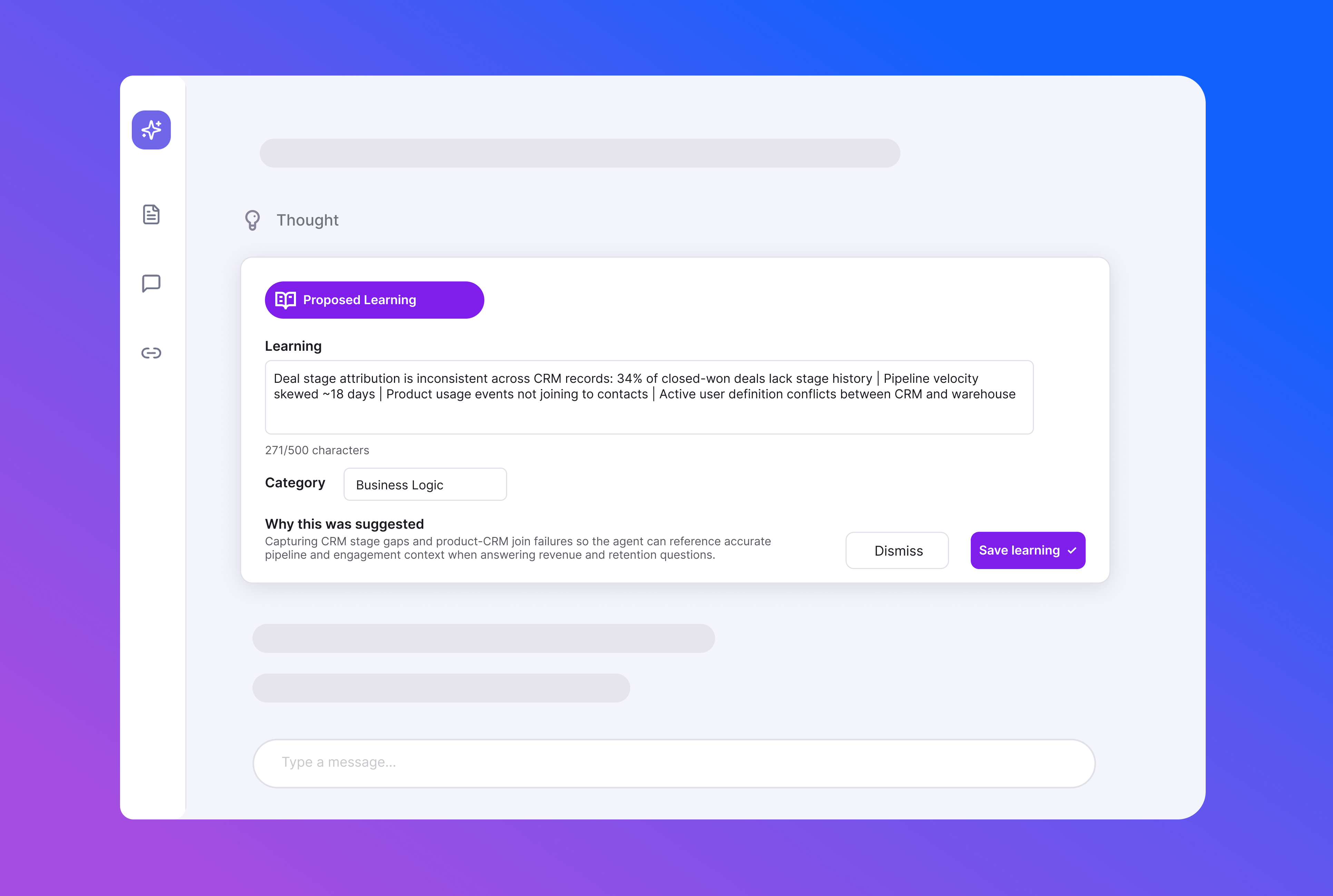
Context drift happens slowly, then all at once. Errors get worse incrementally and then suddenly engagement goes down as trust degrades.
With Adaptive Learning, Bobsled not only collects explicit user feedback but also monitors interactions to identify poor user experiences — catching problems users never think to report
Here are the types of negative signals Bobsled identifies:
- Explicit user feedback (thumbs up/down, written corrections)
- Multiple users correcting an agent
- Inefficient query patterns or logic
Review issues at scale with Progressive Autonomy
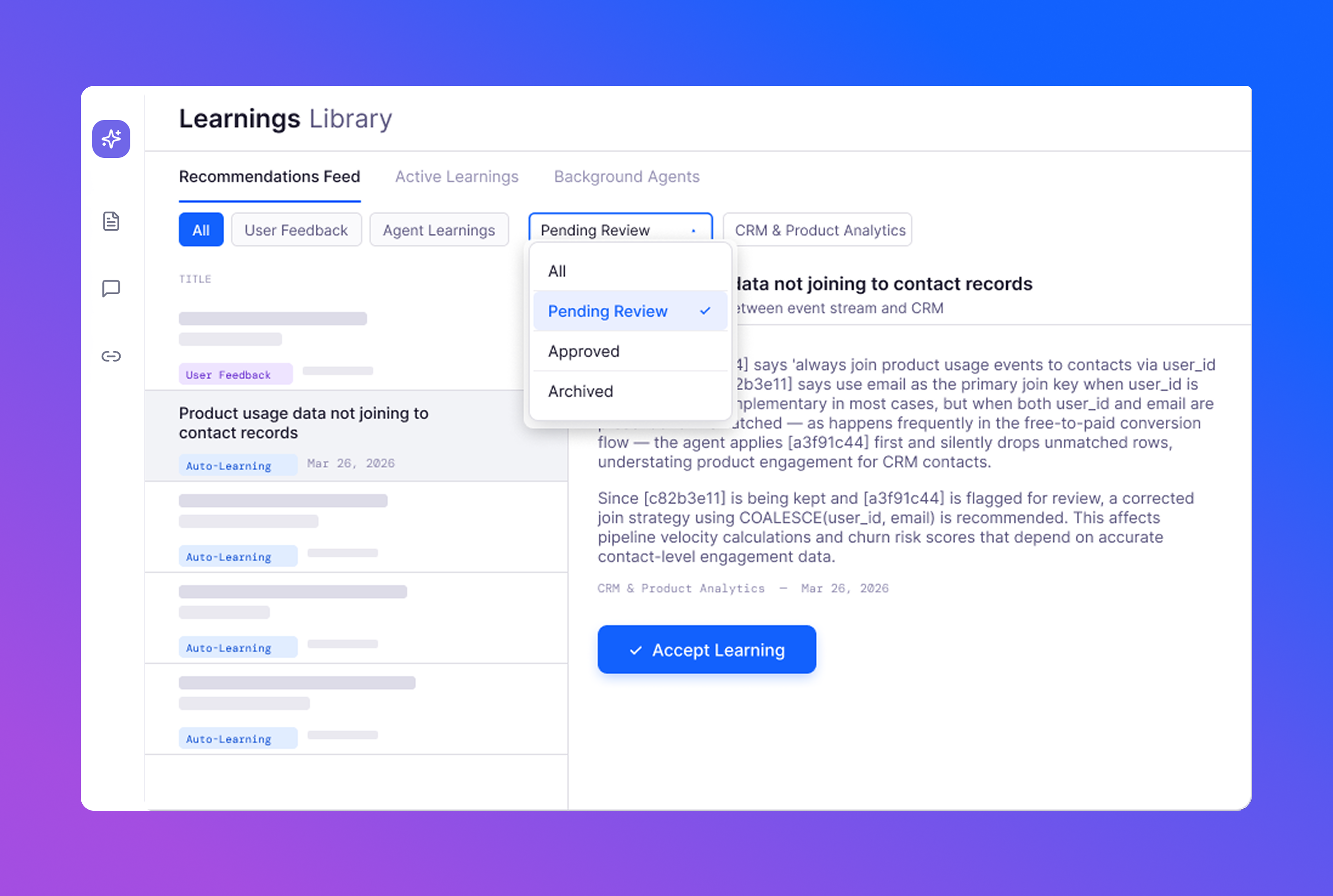
Identifying errors is only half the problem. The harder question is how you manage review and remediation as the volume grows.
Review everything manually and you've recreated the bottleneck. Move too fast toward full automation and you lose control of the system. The right answer is somewhere in between — and it shifts as your team builds confidence in the agent.
That's the idea behind progressive autonomy. Start with significant human oversight, then gradually hand off more decision-making as trust builds.
Starting today, all users have access to the Learnings Center where they can:
- Review learnings generated by the agent
- Approve and edit agent-generated remediations
- Set rules that allow the agent to act autonomously based on the type and scale of the change
Fix the root of the problem with Cross-Stack Remediation
When something breaks, the question is: where? Is it a gap in the context layer? A prompt issue? A data modeling problem?
Bobsled's Adaptive Learning agents don't have to guess. They evaluate across all three, then recommend the fix most likely to solve it for good.
Say your team asks "what's our churn rate?" and gets a different number every time. The agent traces the inconsistency across all three layers and surfaces a fix for each:
- Context layer: No definition of "churned." Add one to the semantic model.
- Prompts: The definition exists but isn't always applied. Add an instruction to enforce it.
- Data model: The agent is inferring churn from raw transactions. Pre-compute it in a derived table.
Building data agents that learn with you
Learning is an essential capability in any agentic analytics experience. Without it, your context decays, your system drifts further from reality with every data model change, and the trust you worked so hard to build erodes quietly in the background. Static systems don't fail dramatically — they just slowly stop being useful.
But when learning works, every interaction is a learning opportunity. One analyst corrects how churn is calculated and every analyst after them gets it right automatically. The tribal knowledge that used to live in one person's head — the person everyone depends on and nobody can replace — starts living in the product itself. The burden of sharing best practices shifts from the user to the platform. That's the difference between a tool and a system that scales.